| |
H4H

septembre 2013 -
Le projet H4H a pour objectif de fournir aux développeurs d’applications de calcul intensif un environnement de programmation parallèle hybride permettant de combiner de façon optimale l’utilisation de différents modèles de programmation parallèle tels que MPI (Message Passing Interface), OpenMP ou HMPP, et d’exploiter ainsi le plus efficacement possible des plates-formes hétérogènes comprenant d’une part des nœuds de calcul dotés de processeurs standards tels que les processeurs Xeon d’INTEL et d’autre part des accélérateurs graphiques tels que les GPGPU (General Purpose Graphics Processing Units) de NVIDIA ou les accélérateurs Intel Xeon PHI qui offrent des gains de performance élevés pour certains algorithmes mais qui sont pour certains particulièrement difficiles à mettre en œuvre en mode hybride.
Cet environnement est donc conçu pour faciliter le processus de développement, de mise au point et d’optimisation des applications scientifiques et techniques de façon à permettre de modéliser plus finement des systèmes complexes et de faire des simulations plus poussées afin d’accélérer la recherche et l’innovation, et d’augmenter ainsi la compétitivité de l’industrie européenne dans des domaines aussi variés que l’exploitation du gaz et du pétrole, la conception aéronautique, les traitements vidéo, le rayonnement électromagnétique, ou la simulation de processus industriels complexes tels que la combustion, le moulage, ou l’emboutissage.
Pour relever ce défi, ce projet associe les compétences des plus grands centres européens de ‘Supercomputing’, de plusieurs laboratoires de recherche en HPC, d’éditeurs renommés d’outils logiciels pour le HPC, du seul fournisseur Européen de plates-formes HPC, et d’un ensemble d’utilisateurs travaillant dans différents domaines qui sont impatients de mettre en œuvre la technologie proposée dans leurs applications scientifiques ou techniques les plus gourmandes en puissance de calcul. Au deuxième semestre 2012, le a été intégré au projet H4H. Ce projet a pour but de fournir une nouvelle génération de système HPC capable de booster facilement les applications scientifiques et industrielles s’exécutant sur des architectures hybrides. se terminera donc fin Octobre 2014.
-
Un ensemble d’extensions des directives HMPP (Hybrid Multicore Parallel Programming) permettant d’exploiter facilement des librairies telles que CuBLAS et CuFFT et de distribuer les données et les calculs sur plusieurs GPUs ;
-
La participation active au
-
L’implémentation d’une partie de l’interface de trace permettant aux outils d’analyse de performance (Scalasca, Vampir, etc.) d’identifier les goulots d’étranglement d’un code HMPP distribué sur une architecture hybride (CPU+GPU) et de faciliter grandement l’optimisation de ce code.
-
L’extension des outils d’analyse de performance, en particulier Vampir et Scalasca, pour permettre l’analyse de code CUDA ou OpenCL utilisés sur les GPUs et le support des tâches d’OpenMP 3.0
-
Le développement de sciGPGPU (Scilab sur GPU) s’appuyant sur CUDA et sur les librairies CuBLAS et CuFFT ; le développement de Scilab MPI permettant de distribuer le code sur plusieurs nœuds de calcul ; ainsi que l’amélioration et le portage sur GPU de la librairie LAMA (Library for Accelerated Math Applications) sur laquelle s’appuie le solveur SAMG. Ces deux éléments, Scilab et SAMG étant ou devant être utilisés dans de nombreuses applications de simulation pour accélérer les phases les plus gourmandes en capacité de calcul parallèle.
-
L’optimisation de l’infrastructure logicielle ‘bullx supercomputing suite’, en particulier de la librairie bullxMPI qui utilise la connaissance fine de la topologie d’un système pour optimiser les échanges de données entre processus ; l’amélioration de la résistance aux fautes grâce à un mécanisme de failover ; l’optimisation de la gestion des tâches et des ressources ; le développement d’optimisations autour de l’approche PGAS (Partitioned Global Address Space) la librairie OpenSHMEM et le développement d’une première version de la gestion de la consommation d’énergie.
-
La restructuration, le portage sur GPU, et l’optimisation d’une vingtaine de cas tests couvrant une grande variété de domaines (seismic imaging, combustion simulation, casting process simulation, Finite Element Systems, molecular modeling, electromagnetic simulation, aerodynamics, audio recognition, and video encoding). Les développeurs d’applications bénéficiant de l’aide des fournisseurs de méthodes et d’outils tandis que ces derniers comprennent mieux les besoins des utilisateurs et les améliorations à apporter en priorité. Les améliorations de performances sont très encourageantes, par exemple, x3 en combinant MPI et l’exploitation de GPU, x1.6 en résolvant des problèmes de hiérarchie mémoire détectés par ThreadSpotter ; x5 en portant le code critique sur GPU avec HMPP.
- Tous ces résultats sont régulièrement présentés dans les grandes conférences HPC comme SC12, PARCO13 et ISC13, ou dans des workshops internationaux tels que Forum Terratec, VI-HPD Tuning workshop, MuCoCoS13. Voir aussi le site web du projet :
| FD-based simulation of vortex shedding behind a Falcon during take-off phase
Courtesy of Dassault-Aviation, France

|
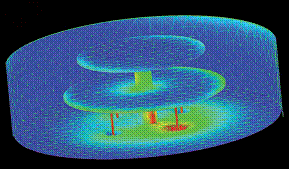
CSimulation of the SWARM GPS antenna using Efield®
Courtesy of SAAB Space AB, Sweden
|
Porteur : BULL
Partenaires du projet : ROGUE WAVE (Su�de) - ATEME (France) - BMAT (Espagne) - BULL (France) - CAPS (France) - CEA-LIST (France) - DA (France) - EFIELD (Su�de) - SCILAB ENTERPRISES (France), FRAUNHOFER SCAI (Allemagne) - GNS (Allemagne) - DATALAB (Espagne) - GWT (Allemagne) - INTES (Allemagne) - JUELICH (Allemagne) - MAGMA (Allemagne) - RECOM (Allemagne) - REPSOL (Espagne), TELECOM-SUDPARIS (France) - TUD (Allemagne) - UAB (Espagne) - USTUTT (Allemagne) - UVSQ (France)
 |
