|
|||
|
|||
Contacts ECR Lab |
UVSQ |
INTEL |
Home > Technopole TERATEC Lab Exascale Computing Research
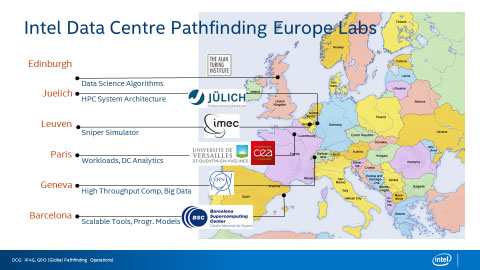
Exascale Computing Research Laboratory The Exascale Computing Research (ECR) laboratory is the result of a collaborative effort between CEA, INTEL and UVSQ (Université de Versailles Saint Quentin en Yvelines). Its teams are active in the research networks dedicated to massive parallelism. ECR is part of Intel Data Center Pathfinding Europe labs, located in France, Belgium, Spain, Germany, Switzerland and Great Britain, which hosts collaborative projects on innovative architectures for HPC or massive data analysis. For the coming years, one of the major challenges to prepare the move towards systems with millions of cores remains optimising interactions between various software levels (particularly applications) and hardware. This makes it necessary to work on a number of fronts: on one hand, by developing sophisticated tools to analyse the behaviour of the different functional units/components within a core and also within the communication network and, on the other hand, by directly working at the level of application Data Science or HPC in order to overcome poor component use or scalability limitations. This cross-expertise between tools and applications knowledge applied to rewrite codes to better benefit from new architectures is at the heart of the collaborative work at ECR.
MAQAO (www.maqao.org) is a modular software aiming at analysing performance for HPC applications. It makes it possible to run very precise « diagnostics » of various performance issues (vectorisation, cache, parallelism) within an application and provides the application developer with a synthetic report of the different analyses (via the ONE VIEW module) to help him select the most rewarding optimisations. In 2017, further work on MAQAO focused on an enrichment of its functionalities: in this respect, we first added a locality evaluation module (On line Locality Evaluator: OLE) which provides the developer with a survey indicating how the memory hierarchy has been used by a fragment of code within an application. We then increased the synthesis capabilities of ONE VIEW (a module making it possible to automatically run different MAQAO modules and to aggregate all the resulting measures). On one hand, the ergonomics have been improved by providing a summarized HTML report making navigation between all of the results much easier. On the other hand, for each loop of the targeted application, we calculate the impact on execution time of applying optimisations such as vectorization or blocking. This functionality is crucial to effectively guide the developer’s optimization work. We also developed a module for an automatic transformation of code (ASSIST). During a first run of the application, ASSIST retrieves the analyses from the different modules in MAQAO in order to identify a group of transformations to be applied on the source code in a further step. The first results validated ASSIST principles on real applications and automatically generated performance gain over 10% on a full execution. Finally, major components of MAQAO have also been updated to take into account the specificities of new generation microprocessors XEON (Skylake) and Xeon PHI (KNL).They have been successfully tested on partners’ applications. The MAQAO team at UVSQ is an active member of the VI-HPS (www.vi-hps.org) community which gathers the main developers of performance analysis OPEN SOURCE tools (TAU, ScoreP, Scalasca, Vampir, ….). In 2017, the MAQAO team took part in two VI HPS Tuning Workshops (Aachen and Teratec). Dozens of HPC code developers were given the opportunity to be trained in the use of MAQAO and furthermore directly test it on their own applications. For the two sessions, participants gave excellent feedbacks with respect to both the relevance and the quality of the diagnostics provided by MAQAO, which has been ranked among the 3 best tools to be used. Numerical simulation at a large scale often raise trade-offs between performance and numerical precision. To allow a thorough and precise exploration of these trade-offs, Verificarlo (http://github.com/verificarlo) estimates the numerical precision within large applicative codes. Verificarlo relies on Monte Carlo arithmetic in which random noise is added to computational operators to model rounding or cancellation errors, in a stochastic process. Code instrumentation is performed by the tool during compilation, through a specific LLVM pass, without any need to modify the program source code. This usage transparency, made the analysis of several industrial codes with Verificarlo possible. In 2017, Verificarlo has been extended with tracing functionalities to visually plot the loss of precision across time during the execution of complex applications such as ABINIT. Verificarlo and its application to the EuroPlexus code were presented during Teratec forum (https://teratec.eu/forum_2017/atelier_8_01.html). Optimising runtime systems in a context of High Performance Computing is critical as they are the link between hardware and applications. The MPC runtime system (http://mpc.hpcframework.com), originally developed by CEA, was built in order to facilitate the development and the optimisation of parallel applications on multi/many core machine clusters. MPC provides unified models of programming as well as the MPI and Open MP implementations classically used by parallel applications. MPC also offers a HPC ecosystem with a multithread/NUMA memory allocator, support for user’s threads (debugger, extended GCC compiler, …), some compiler extensions dedicated to data sharing, …. as well as an integration with more recent programming models such as Intel TBB. At the beginning of 2017, the ECR Runtime team has pursued some developments in the parallel open-source MPC platform. Some part of this work led to version 3.2 including new functionalities (GCC version 6.2.0 is integrated, tasks with Open MP dependencies, MPIT as well as RMA one-way communication are supported, …). For the rest of the year, focus has been put on different aspects: optimisations for Intel Xeon Phi KNL processors, better compatibility of the interface with Intel compiler and development of a tool to detect threads/process placement. It is then possible to check how resources are used in terms of placement of MPI process and Open MP threads through an automatic algorithm or an interface based on the HWLOC tool.
In June 2017, CFD experts from CERFACS, CORIA, Cenaero, CEA, Université de Versailles Saint Quentin (UVSQ) and Intel led a week-long session, devoted to training on new tools/architectures and optimizing CFD applications. For the selected codes, YALES2, AVBP et ARGO, improving their performances on Intel® Xeon Phi ™ et Intel® Xeon® Scalable processors with the most advanced tools (MAQAO, Vtune) was the main goal. It was also a matter of getting ready for a broader diffusion, taking into account the impact of these codes, for example in the establishment of the aeronautical platform aeronautical of the technological group SAFRAN. The VI-HPS Consortium (www.vi-hps.org) gathers the main academic institutions developing open source performance analysis tools : Jülich Supercomputing Center, Technische Universität Dresden, Universität Stuttgart, Technische Universität Munchen, RWTH Aachen, Université de Versailles Saint Quentin en Yvelines, Barcelona Supercomputing Center, Lawrence Livermore Laboratory, University of Oregon, University of Tennessee. Created in 2007, this consortium has ever since promoted the use of the tools developed by its members. Thus, every year, both a workshop and a tutorial session have been organised at SC conference (Supercomputing). Also, Tuning Workshops take place two or three times a year. During these 5 days long Tuning Workshops, not only the tools from the different partners are presented but participants can also test these tools on their own applications during hands-on sessions. ECR organised the 26th session of this Tuning Workshop on the site of TERATEC from October 16th to 20th (see detailed program at http://www.vi-hps.org/training/tws/tw26.html). CEA provided the necessary hardware infrastructure, in particular INTI machines which made it possible to implement all the tools and make the hands-on sessions successful. This Tuning Workshop attracted 20 participants from both academia (CEA, CORIA, X, UVSQ, EPFL) and industry (EOLEN, NEOXIA). Various applicative domains were represented; from classical ones such as CFD or molecular dynamic to “hotter” ones such as Machine Learning and Blue Brain Project.
|
|